Gene Annotation
 Next-generation sequencing (NGS) technologies have led to the accumulation of high-throughput sequence data from various organisms in biology. To apply gene annotation of organellar genomes for various organisms, more optimized tools for functional gene annotation are required. Almost all gene annotation tools are mainly focused on the chloroplast genome of land plants or the mitochondrial genome of animals. We have developed a web application AGORA for the fast, user-friendly and improved annotations of organellar genomes. Annotator for Genes of Organelle from the Reference sequence Analysis (AGORA) annotates genes based on a basic local alignment search tool (BLAST)-based homology search and clustering with selected reference sequences from the NCBI database or user-defined uploaded data. AGORA can annotate the functional genes in almost all mitochondrion and plastid genomes of eukaryotes. The gene annotation of a genome with an exon–intron structure within a gene or inverted repeat region is also available. It provides information of start and end positions of each gene, BLAST results compared with the reference sequence and visualization of gene map by OGDRAW.
Next-generation sequencing (NGS) technologies have led to the accumulation of high-throughput sequence data from various organisms in biology. To apply gene annotation of organellar genomes for various organisms, more optimized tools for functional gene annotation are required. Almost all gene annotation tools are mainly focused on the chloroplast genome of land plants or the mitochondrial genome of animals. We have developed a web application AGORA for the fast, user-friendly and improved annotations of organellar genomes. Annotator for Genes of Organelle from the Reference sequence Analysis (AGORA) annotates genes based on a basic local alignment search tool (BLAST)-based homology search and clustering with selected reference sequences from the NCBI database or user-defined uploaded data. AGORA can annotate the functional genes in almost all mitochondrion and plastid genomes of eukaryotes. The gene annotation of a genome with an exon–intron structure within a gene or inverted repeat region is also available. It provides information of start and end positions of each gene, BLAST results compared with the reference sequence and visualization of gene map by OGDRAW.
https://bigdata.dongguk.edu/gene_project/AGORA/
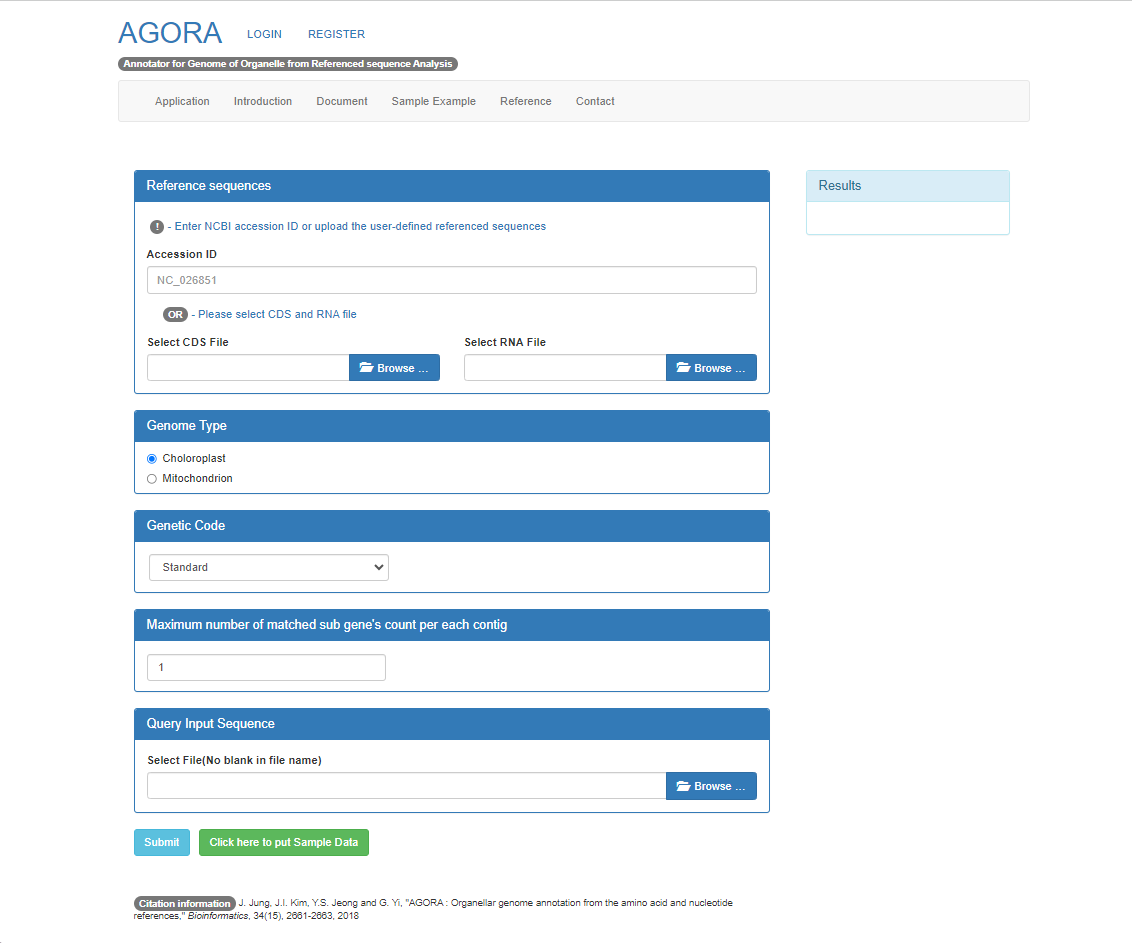
Input
Reference sequence:
- In order to run the BLAST with query and references, you need to put reference sequences. If you have the user-defined amino acid or nucleotide sequences, you can upload it on the system. Otherwise, you can put the accesion number such as NC_000000.For more information, please refer NCBI site
Input File Format:
- Input file is an assembled contig. The format should be “FASTA”. The AGORA allows only one assembled query contig. For more information about FASTA, please refer to NCBI site
Type:
- Select Choloroplast or Mitochondrion for your organellar genome
Genetic Code:
- This code is used for running the tBLASTn
- Standard
- Vertebrate Mitochondrial
- Yeast Mitochondrial
- Mold Mitochondrial
- Invertebrate Mitochondrial
- Ciliate Nuclear
- Echinoderm Mitochondrial
- Euplotid Nuclear
- Bacteria and Archaea
- Alternative Yeast Nuclear
- Ascidian Mitochondrial
- Flatworm Mitochondrial
- Blepharisma Macronuclear
For more information about genetic code please see NCBI
Output
Output:
- As you see below examples, output file is the BLAST result that includes amino acid and nucloetide. The Query is set to the refereces and Data base is set to query. The number of matched position is decided upon the “Maximum matched sub gene’s count”
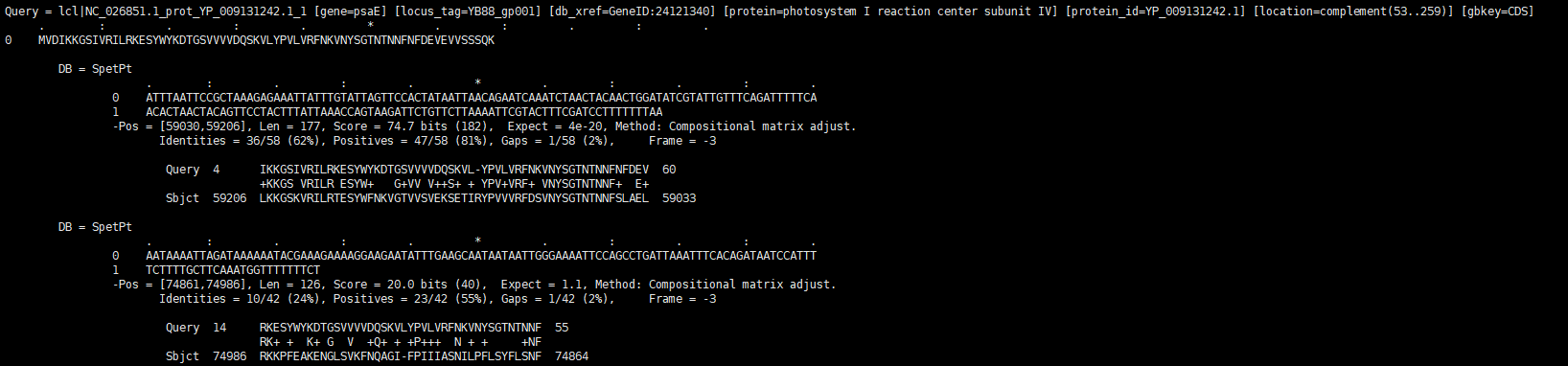
The blast result of amino acid
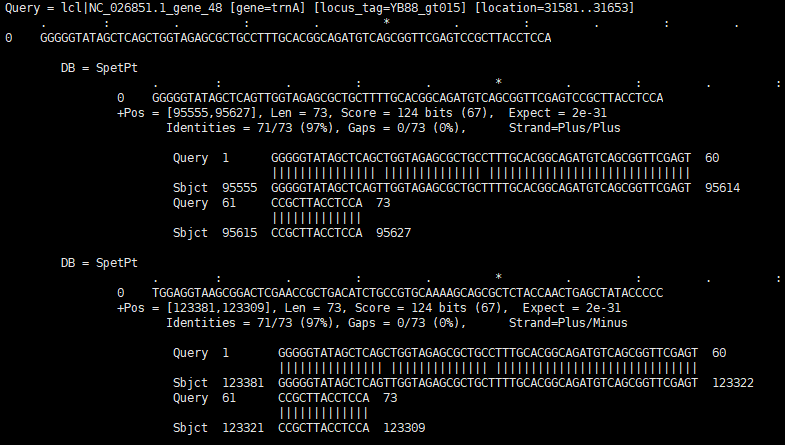
The blast result of nucleotide
Amino acid db sequences:
- This file includes the amino acid data base sequences. If the user uploaded the user-defined sequence, this file is same to that uploaded file. Otherwise, system is automatically generated from the NCBI.
Amino acid sequences:
- This is CDS translation files that is matched from the BLAST
Output CSV file:
- This file provides the start and end position, direction and gene product for each gene.
Nucleotide db sequences:
- This file is nucleotide data base sequences.
Nucleotide sequences:
- The FASTA formatted sequences file is includes the BLAST matched sequences.
GenBank File format:
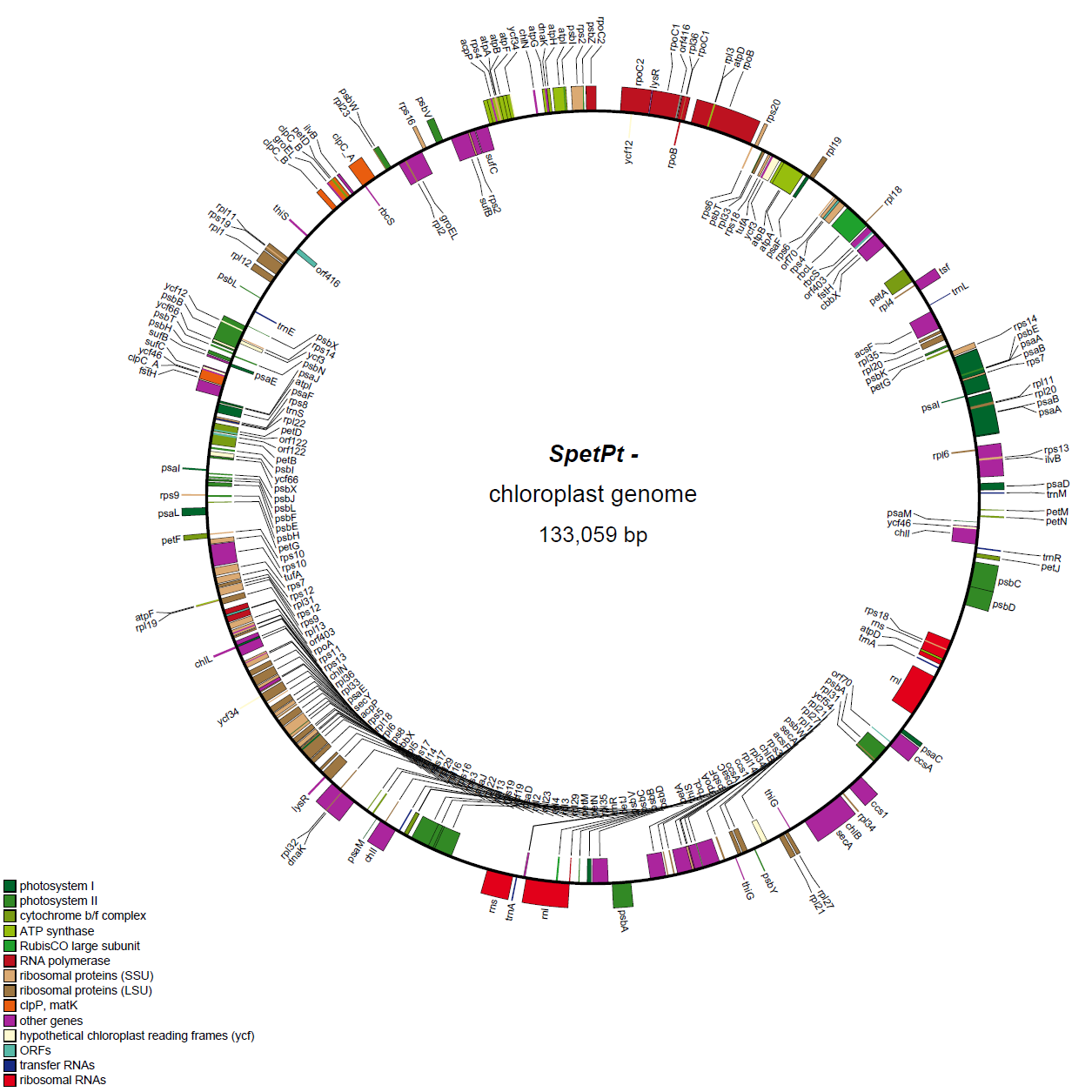
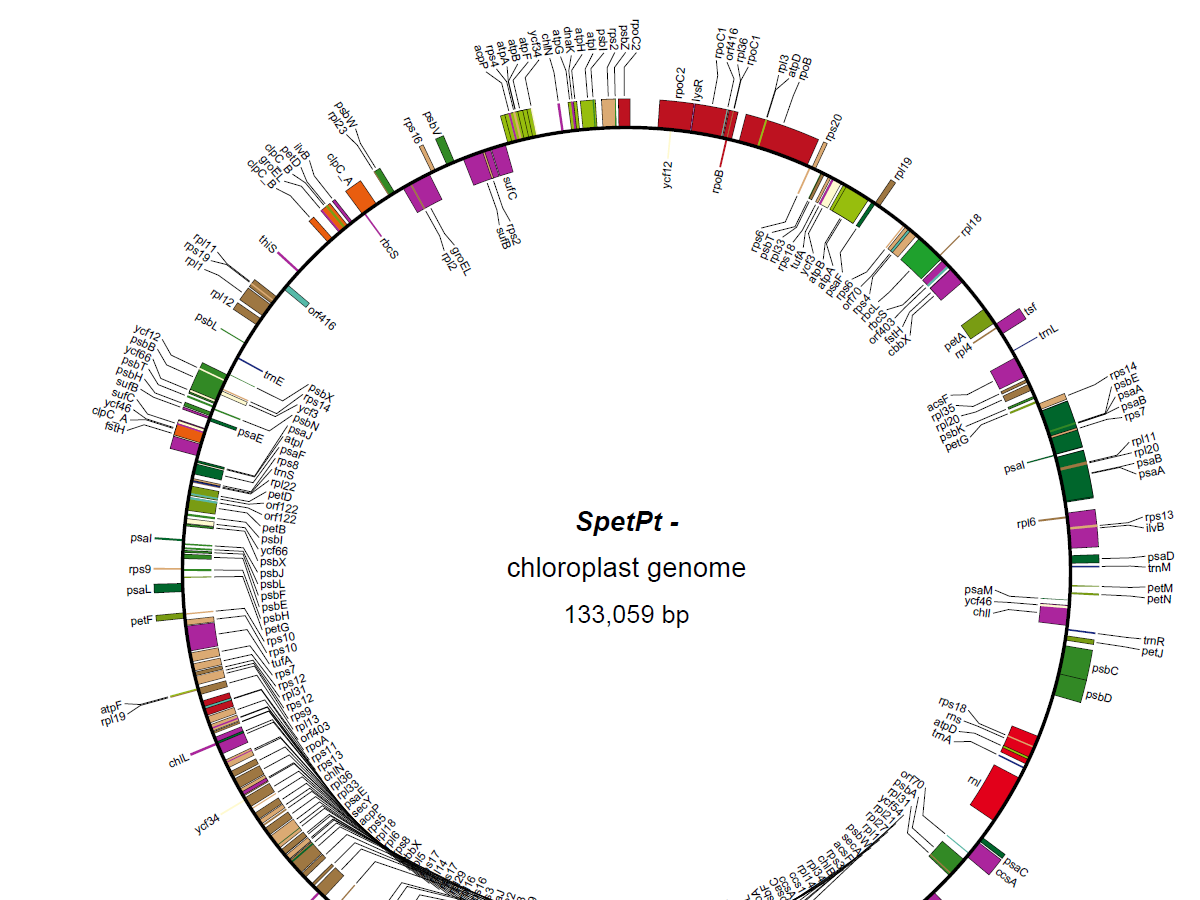
- This file is GenBank formatted file. With this file we draw the circular gene map by running OGDRAW
OGDRAW:
- If all genes are matched correctly, you can see the figure. Here is example